AMD新专利,解决多芯粒GPU延迟
据报道,基于最新获批的专利,AMD 公司已探索「智能交换器」优化数据处理,从而解决多芯粒 GPU 的延迟问题。有消息称在消费级 GPU 领域,AMD 预计将采用多芯粒模块设计。
多芯粒模块设计,即将多个芯片集成到一个封装中,之前已在高性能计算领域得到应用,而 AMD 计划将其扩展到游戏 GPU,以应对单芯片设计在制造和性能上的瓶颈。
此前,AMD 在这方面积累了丰富的经验,例如其 Instinct 系列加速器已采用多芯片设计。Instinct MI200 使用多个图形计算芯片与高带宽内存堆叠,实现了高效的数据传输。后续的 Instinct MI350 系列进一步优化了这一结构,搭载 288GB HBM3E 内存,内存带宽达 8TB/s,基于 3nm 工艺节点,总晶体管数达 1850 亿。该系列通过 10 个芯片模块的 2D 混合键合,提升了 AI 任务的处理能力,为消费级产品提供了技术基础。
具体到游戏领域,GPU 若要采用多芯粒模块设计,那么最大的问题就是延迟较高,因为帧渲染对长距离数据传输的延迟非常敏感。若要解决这一问题,AMD 就必须想出一种能尽可能缩小数据与计算之间差距的方案。
根据披露的一项新专利申请,AMD 或许已经破解了多芯粒模块设计游戏 GPU 的设计之道。不过,该专利视频中披露的是 CPU 相关细节,而非 GPU,但文本内容和机制表明其目标是图形应用场景。
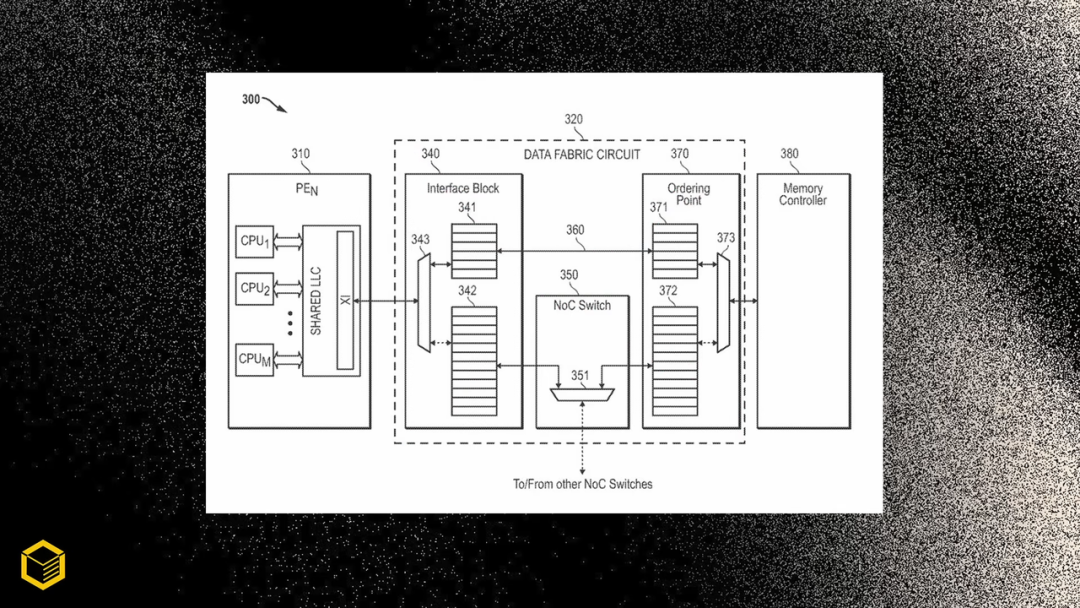
那么,AMD 究竟将如何在 GPU 中运用多芯粒模块设计呢?据悉,该专利的核心是一种「带有智能交换机的数据架构电路」,它能连接计算小芯片与内存控制器之间的通信。这本质上是 AMD
那么,AMD 究竟将如何在 GPU 中运用多芯粒模块设计呢?据悉,该专利的核心是一种「带有智能交换机的数据架构电路」,它能连接计算小芯片与内存控制器之间的通信。这本质上是 AMD Infinity Fabric,但为消费级 GPU 进行了缩减,因为 AMD 无法采用 HBM 内存芯片。该交换机旨在优化内存访问,其工作原理是先判断图形任务请求是否需要任务迁移或数据复制,决策延迟达到纳秒级。
解决了数据访问问题后,该专利还指出要让图形计算核心(GCD)配备 L1 和 L2 缓存,这与 AI 加速器的设计类似。不过,通过交换机还能访问额外的共享 L3 缓存(或堆叠式 SRAM),该缓存将连接所有 GCD。这不仅减少了对全局内存的访问依赖,同时能够充当小芯片之间的共享过渡区,类似于 AMD 3D V-Cache 技术,只不过 3D V-Cache 主要用于处理器。此外,该专利还涉及堆叠式 DRAM,这本质上是多芯粒模块设计的基础。
这一专利的出现表明,AMD 已为多芯片 GPU 生态做好准备。AMD 可以使用台积电的 InFO-RDL 桥接技术,以及在小芯片之间使用特定版本的 Infinity Fabric 进行封装。更具吸引力的是,这种实现方式是 AI 加速器的缩减版本。此前,AMD 计划将其游戏和 AI 架构合并为一个统一架构,即 UDNA 架构。AMD 还整合了软件生态系统,这样可以摊薄驱动程序和编译器的开发工作。
由于单芯片设计存在局限性,这或许是 AMD 超越竞争对手的绝佳机会。然而,芯粒设计也存在复杂性,AMD 此前在 RDNA 3 上就曾遇到过小芯片互连带来的延迟。AMD RDNA 3 架构 Navi 31 GPU 已部分采用多芯片设计,配备六个内存控制器芯片,总 Infinity Cache 达 96MB,内存总线宽 384 位,支持高达 24GB GDDR6 内存。通过 Infinity Fabric 互联,峰值带宽达 5.2TB/s。该设计在 RX 7900 系列中实现,每瓦性能较前代提升 50%,但也暴露了芯片间延迟的缺陷。
然而凭借创新的交换机方案,再加上额外的共享 L3 缓存,AMD 有望解决延迟问题。不过,具体效果如何,可能要到 UDNA 5 才能见分晓。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码

