Anthropic打造的 “不完美巨兽”Mythos
我们已知晓Anthropic推出了全新的Mythos 模型的情况,不得不说虽然Anthropic跟美国政府闹掰了,但这款产品简直是为特朗普政府量身定制般极具吸引力。事实上,对任何一位身处白宫、尤其面临来自伊朗、俄罗斯网络威胁的美国总统而言,它同样极具诱惑力。
Mythos 的能力层级更高,智能程度也远超该公司两年来主推的 Opus 混合专家模型。Opus 此前仅向少数科技巨头开放,原因在于其危险性极高 —— 它能精准挖掘全球海量存量软件中的安全漏洞,构成重大网络安全风险。
本周早些时候,Anthropic 在发布 Mythos 预览版时,并未过多透露这款即将面世的模型架构,也未说明何时会向公众开放。但这款模型被悄悄藏在一则关于 “琉璃翅计划(Project Glasswing)” 安全项目的公告中,着实让所有人惊出一身冷汗。
Anthropic 在公告中写道:“Mythos 预览版已发现数千个高危安全漏洞,覆盖所有主流操作系统与网页浏览器。”—— 这是官方重点强调的内容,并非笔者杜撰。“鉴于人工智能技术迭代速度,此类能力很快会扩散,可能落入无法安全运用它的主体手中。这对全球经济、公共安全与国家安全造成的后果将极为严重。琉璃翅计划正是为了将这些能力用于防御目的而紧急启动的项目。”
也正因如此,Anthropic 与亚马逊云科技、苹果、博通、思科、克劳德强袭、谷歌、摩根大通、Linux 基金会、微软、英伟达以及帕洛阿尔托网络公司达成合作,这些企业正借助 Mythos 模型排查自身代码中的安全漏洞。或许它们还能用 Mythos 修复这些漏洞?也或许在重新编译代码后,模型不会在代码中埋下任何隐患……
本刊物聚焦系统架构,而非技术对社会、文化与商业的影响。但我们仍认为,一家头部大模型厂商因担忧其成果失控而选择不公开发布,这一事件值得高度关注。没人断言 Mythos 未来绝不会以某种形式面世,但至少有一家模型研发方在审慎考量 —— 并非因为模型质量不佳,恰恰相反,是因为它在自身领域强悍得过分。
这是非同寻常的一周里,一个格外诡异的时刻。
与 Claude 系列的 Haiku、Sonnet、Opus 等版本一样,Anthropic 对 Mythos 的细节守口如瓶。官方未提及参数量与训练数据集规模,尽管所有模型厂商都宣称这些指标已不再重要。可想而知,笔者对此完全不敢苟同。训练数据集的规模与质量、模型总参数量,以及混合专家模型中可同时激活的参数量,这些因素绝对至关重要。所有厂商都不愿公开,只因一旦披露,外界就能推断出其模型结构与运行逻辑。
不过,我们仍能从琉璃翅计划公告、Mythos 预览版技术深度解析,以及官方发布的系统说明卡(也就是我们常说的规格表)中挖掘出一些信息。Mythos 预览版的对齐风险评估报告可在此查阅。
Mythos 的研发代号为 “水豚(Capybara)”—— 这种产自南美洲、体重近 70 公斤的水栖啮齿动物,若历经足够漫长的岁月(比如 5000 万年),或许会进化成近似海豚的生物。很难说 Anthropic 为何以此命名,但从基准测试结果可以明确:Mythos 与该公司主打对话的 Sonnet、侧重推理的 Opus 模型相比,实现了质的飞跃。它可能依旧是混合专家架构,也可能是一种全新技术路线。
Mythos 的上下文窗口与当前最新版 Sonnet 4.6、Opus 4.6 一致,为 100 万 token,但我们有充分理由相信,其设计初衷是支持远超这一规模的扩展。坊间传言 Mythos 参数量达 10 万亿,但据笔者所知,尚无可靠信源佐证。Mythos 是一款推理型模型,能力被认为优于 Opus,不过它最终是否会正式商业化仍未可知。
Anthropic 前沿安全红队负责人洛根・格雷厄姆上周接受 NBC 新闻采访时,如此评价 Mythos:“这款模型的自主决策能力、长程规划能力,以及整合多维度信息的能力,是其最突出的特质。”Mythos 系统说明卡描述道:该模型如同协作伙伴,观点鲜明、立场坚定,表达凝练密集,默认使用者与它具备相同背景,拥有辨识度极强的语言风格,能清晰描述自身运行逻辑,且犯错方式十分隐蔽、不易察觉。(如果你觉得这描述像极了身边某类人,绝非你一人这么想……)
从系统说明卡公布的基准测试数据中,我们可以推断出以下结论:
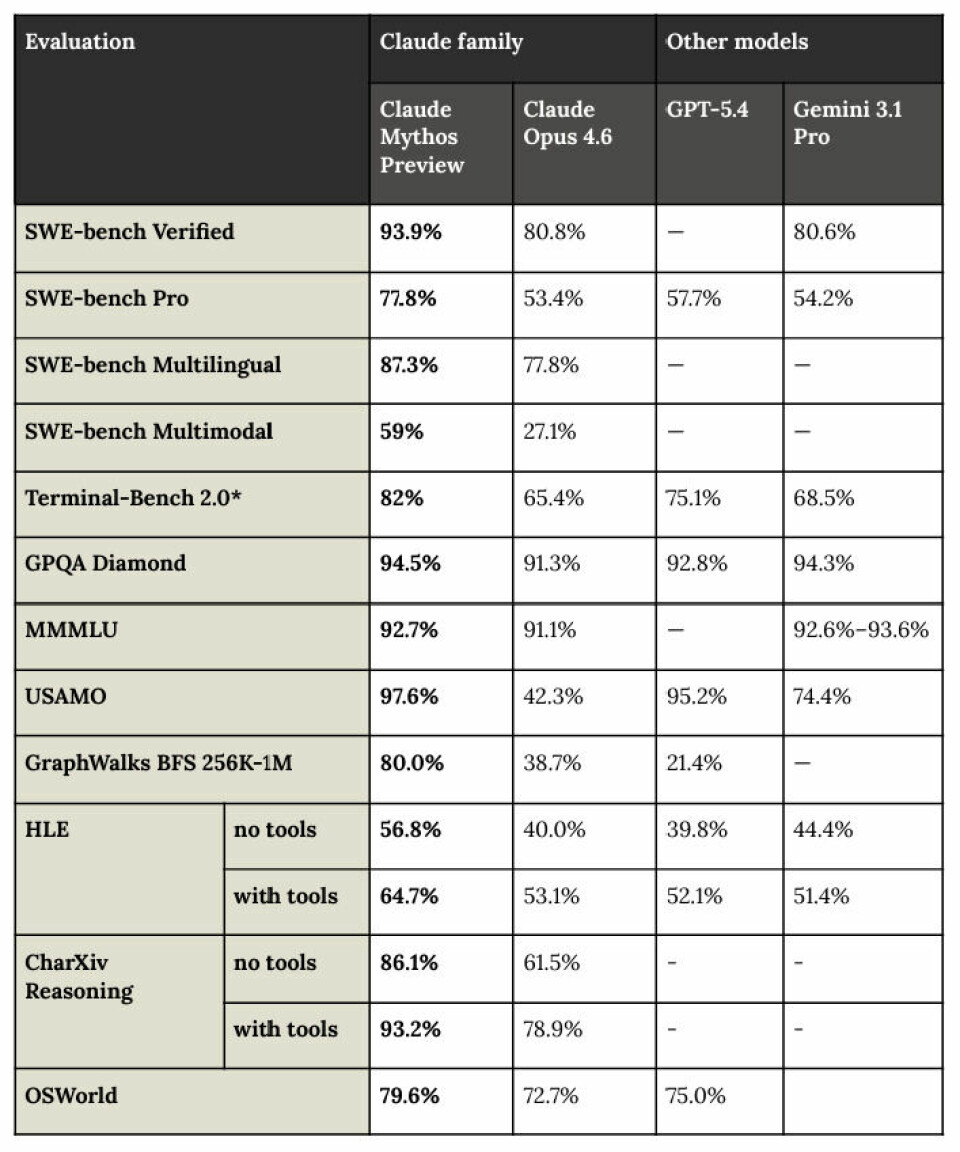
这份对齐风险更新报告评估了 Mythos 的安全性与潜在危害,其中明确指出:“Mythos 预览版与 Claude Opus 4.6 的能力差距,远超该公司过往历代模型间的代差。”
由此我们推测,Mythos 很可能采用了某项突破性技术,实现了跨越式升级。这一点在 SWE-bench 代码助手基准测试、GraphWalks BFE 测试中体现得尤为明显 —— 后者要求模型在海量十六进制哈希图谱中完成推理,专门检验 “上下文退化” 问题,即模型是否会偷懒忽略超大上下文窗口,仅依赖记忆内容作答(当然,我们不必过度拟人化解读)。在 “人类终极考试”(名称颇具讽刺意味,并非选择题,而是包含模型无法解答、领域专家虽感棘手但仍能解决的难题)与 Charxiv 推理基准测试(检验模型基于图表、表格、图形推理的能力)中,Mythos 相较 Opus 4.6 的性能跃升,证明其搭载了 Opus 4.6、OpenAI 的 GPT-5.4 与谷歌 Gemini 3.1 Pro 均不具备的核心创新。最后,在美国数学奥林匹克竞赛(USAMO)测试中,Mythos 展现出极强的复杂数学问题求解能力,大幅优于 Opus 4.6,显著领先 Gemini 3.1 Pro,与 GPT-5.4 旗鼓相当。
直白总结:所有人都想得到 Mythos 模型,而 Anthropic 一方面心怀顾虑,另一方面或许也在刻意吊足市场胃口。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码



