云计算技术及其应用
对于服务器虚拟化的异构问题,可以从两个层面去解决:(1)通过资源池的分组,对不同架构的服务器和小型机进行虚拟化,不同架构的资源池归于一个独立的组,针对不同的应用,分配特定的虚拟机资源。(2)通过业务的定制和调度,将不同架构的虚拟化平台通过管理融合,实现异构虚拟机的调度。
异构资源池如图2所示。在云计算平台中,把IBM的PowerSystems小型机集群通过IBM的PowerVM系统虚拟为基于 PowerSystems架构的计算资源池,把HP的小型机集群通过HP的VSE系统虚拟为基于HP架构的计算资源池,把X86架构的计算资源通过 XENKVM系统虚拟为基于X86的ZXVE资源池。在业务部署时,不同的应用的可以根据自己的业务特点和操作系统特点,选择性地部署在不同的资源池上,从而实现虚拟化对各类小型机的异构。X86架构的计算资源池、PowerSystems架构的计算资源池和HP架构的计算资源池分别受各自的虚拟化管理软件(如VMM、IVM和gWLM)管理。在VMM、IVM和gWLM的上层,可以通过融合的虚拟化管理器(iVMM),对3个计算资源池进行统一管理。
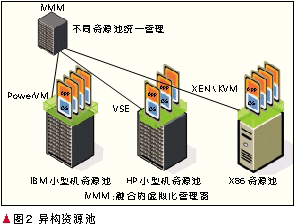
图3所示为虚拟资源对应用实现异构的方法。此方法的核心在于4个方面:iVMM、业务调度器、业务系统针对不同的资源池架构提供应用功能相同的不同版本、iVMM和业务调度器之间的OCCI扩充接口。
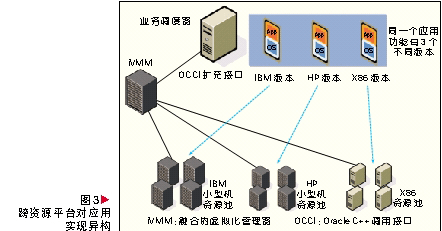
在业务应用层面,针对业务系统,本文增加业务调度器模块。业务调度器根据业务的繁忙程度,向iVMM申请增加或减少虚拟机资源,并调整负载均衡策略。业务系统针对不同的资源池架构,需要准备与之对应的功能相同的不同版本。OCCI扩充接口的工作流程为:
业务系统的业务调度器通过OCCI接口向云计算平台申请资源,同时向云计算平台提供业务系统可以支持的操作系统等信息,并提供优先级信息。
云计算平台根据业务系统的请求和云内资源的空闲情况,分配计算资源,通过OCCI接口通知业务调度器云计算平台向业务系统提供了何种架构的计算资源。
业务调度器根据申请到的资源情况,将业务处理机的操作系统、业务版本等模板信息通过OCCI接口通知云计算平台,由云计算平台进行操作系统和业务程序的部署,完成后提交给业务系统进行使用。
3 分布式技术
分布式技术最早由Google规模应用于向全球用户提供搜索服务,因此必须要解决海量数据存储和快速处理的问题。其分布式的架构,可以让多达百万台的廉价计算机协同工作。分布式文件系统完成海量数据的分布式存储,分布式计算编程模型MapReduce完成大型任务的分解和基于多台计算机的并行计算,分布式数据库完成海量结构化数据的存储。互联网运营商使用基于Key/Value的分布式存储引擎,用于数量巨大的小存储对象的快速存储和访问。
3.1 分布式文件系统
分布式文件系统的架构,不管是Google的GFS还是Hadoop的HDFS,都是针对特定的海量大文件存储应用设计的。系统中有一对主机,应用通过文件系统提供的专用应用编程接口(API)对系统访问。分布式文件系统的应用范围不广的原因主要为:主机对应用的响应速度不快,访问接口不开放。
主机是分布式文件系统的主节点。所有的元数据信息都保存在主机的内存中,主机内存的大小限制了整个系统所能支持的文件个数。一百万个文件的元数据需要近 1G的内存,而在云存储的应用中,文件数量经常以亿为单位;另外文件的读写都需要访问主机,因此主机的响应速度直接影响整个存储系统的每秒的读入输出次数 (IOPS)指标。解决此问题需要从3个方面入手:
(1)在客户端缓存访问过的元数据信息。应用对文件系统访问时,首先在客户端查找元数据,如果失败,再向主机发起访问,从而减少对主机的访问频次。
(2)元数据信息存放在主机的硬盘中,同时在主机的内存中进行缓存,以解决上亿大文件的元数据规模过大的问题。为提升硬盘可靠性和响应速度,还可使用固态硬盘(SSD)硬盘,性能可提升10倍以上。
(3)变分布式文件系统主机互为热备用的工作方式为1主多备方式(通常使用1主4备的方式),通过锁服务器选举出主用主机,供读存储系统进行改写的元数据访问服务,如果只是读访问,应用对元数据的访问将被分布式哈希表(DHT)算法分配到备用主机上,从而解决主机的系统“瓶颈”问题
对于分布式文件系统,外部应用通过文件系统提供的专用API对其进行访问,这影响了分布式文件系统的应用范围。对于标准的POSIX接口,可以通过 FUSE的开发流程实现,但将损失10%~20%的性能。对于网络文件系统(NFS),在实现POSIX接口的基础上,可以直接调用Linux操作系统的 NFS协议栈实现。
3.2 Key/Value存储引擎
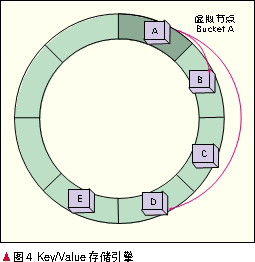
Key/Value存储引擎最大的问题在于路由变更后,数据如何快速地实现重新分布。Key/Value存储引擎如图4所示。可以引进虚拟节点的概念,将整个Key值映射的RING空间划分成Q个大小相同的Bucket(虚拟节点,Key的映射算法推荐采用MD5)。每个物理节点根据硬件配置情况负责多个 Bucket区间的数据。同一个Bucket上的数据落在不同的N 个节点上,通常情况下N =3。我们将DCACHE的Q设定成10万,即把整个RING空间分成了10万份,如果整个DCACHE集群最大容量为50 TB,每个区间对应的数据大小仅为500 MB。对500 MB的数据进行节点间的迁移时间可以少于10 s。图4中,N =3,Bucket A中的数据存储在B、C、D 3个节点。
Key/Value存储引擎是一个扁平化的存储结构,存储内容通过Hash算法在各节点中平均分布。但是在一些应用中,业务需要对Key/Value存储引擎进行类似目录方式的批量操作(如在CDN项目中,网站向CDN节点推送内容时,需要按照网页的目录结构进行增加和删除),Key/Value存储引擎无法支持这样的需求。可以在Key/Value存储引擎中增加一对目录服务器,存储Key值与目录之间的对应关系,用于对目录结构的操作。当应用访问 Key/Value存储引擎时,仍然按照Hash方式将访问对应到相应的节点中,当需要目录操作时,应用需要通过目录服务器对Key/Value存储引擎进行操作,目录服务器完成目录操作和Key/Value方式的转换。由于绝大多数项目中,大部分为读操作,因此目录服务器参与对Key/Value引擎访问的次数很少,不存在性能“瓶颈”。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码