从4004到core i7:处理器的进化史(3)-4-第一次加速
现在加入流水线。为了将每个环节分割开来,我们需要在环节之间加入寄存器以隔离相邻的环节,获得独立的输入、输出。不妨假设在相邻环节之间插入只一个寄存器。其具有自己的时间约束t_c,q(寄存器从输入到输出的传输延时)和t_su(建立时间,这常常和具体的电路结构有关)。为了保证正确性,需要有:
由于我们将整个电路分割成了很多个很小的部分,因此max(t_pd)一般要远远小于t_pd,logic,也就是说,我们可以大大提升时钟频率,这与前面的叙述是一致的。
然而上面的t_c,q和t_su却给我们提了一个醒:
主频的提升并非没有代价,它实际上是以一条指令完整执行的时间(latency)的延长(它现在需要通过很多级寄存器了)来换取吞吐量(throughput,即单位时间内流经某一级的指令数量)的提升。
在指令流连续时,一切都很美好;但是一旦指令流中断(最典型的当然是branch),引入pipeline的额外开销就显著地体现出来了。这里我再自己写一个公式:
T_sum=T_latency+N*T_min,pipe
其中T_sum是执行一段很长很长的指令流的总用时(第一条IF到最后一条WB),N是指令数。这样,我们得到了一种衡量性能的方法:
t_avg=T_latency/N+T_min,pipe
不难想象,当N很小时,很长的pipleline带来的巨大的latency将会让平均指令执行时间t_avg变得很难看。
事实上还有一个限制主频疯狂提升的因素。记得吗,那就是我前面说过的功耗!
正因为以上的两个因素,intel虽然曾经将netburst的流水线做到了28级,频率提高到3.8GHz,甚至差一点就发布了4GHz的Pentium 4,却最终冷静了下来,不再通过越来越深的pipeline不顾一切地提升时钟频率了。
作为参照,core架构的流水线仅14级。
pipeline并不是万灵药,我们需要另外的加速方法。
说完了pipeline,你应该就能看懂这张386的图了:
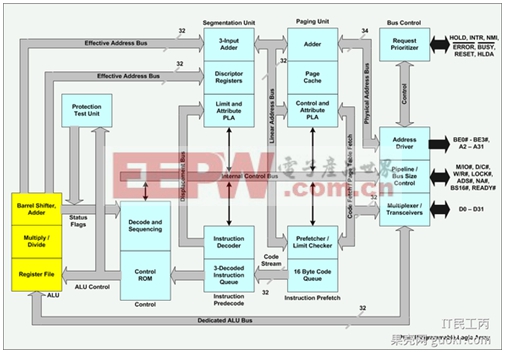
Pipeline is everywhere!!


加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码
